| N | Number of customers. |
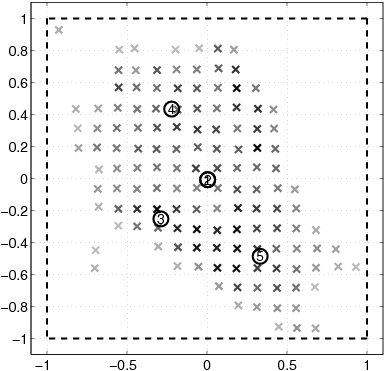
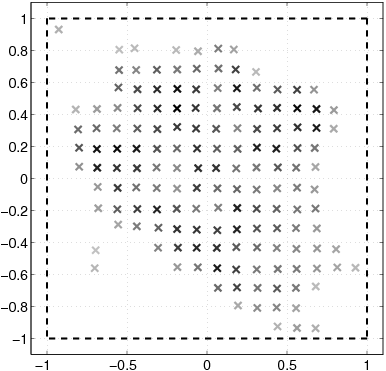
| X | Set of all customers. |
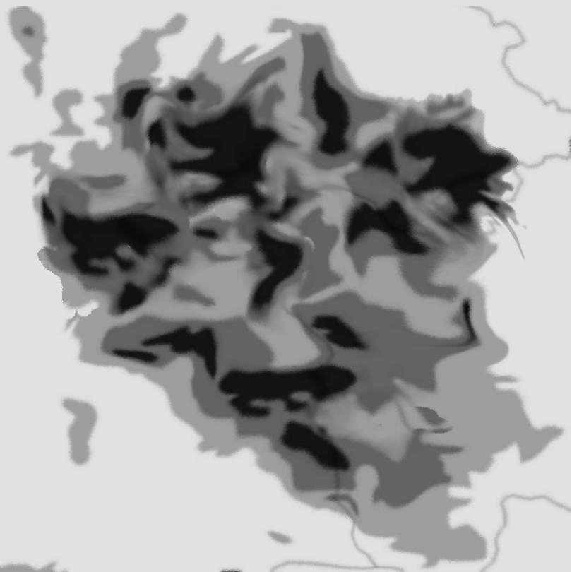
| [(x)\vec] | Location of one customer. |
| m[(x)\vec] | Weight of customer [(x)\vec]. |
| l | Library size. |
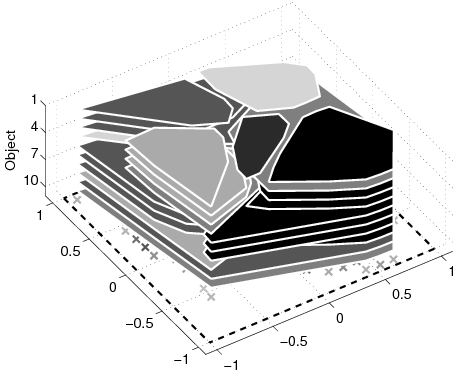
| dj | Popularity of object j. |
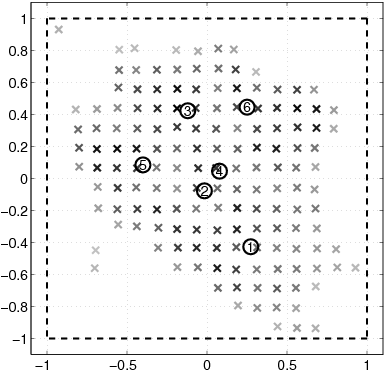
| n | Number of nodes. |
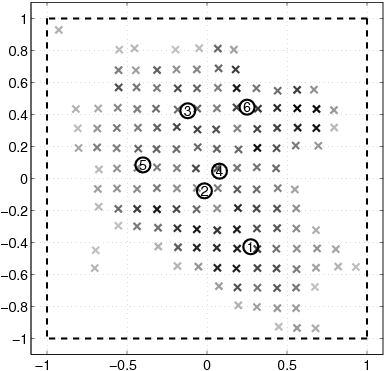
| [(n)\vec]i | Location of node i. |
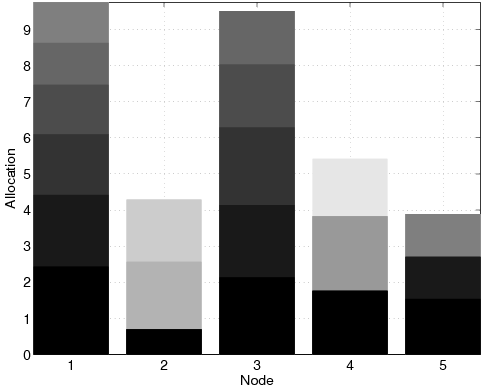
| li | Total resources of node i. |
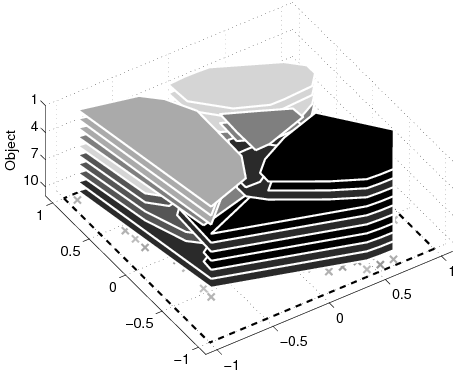
| Lij | Allocation for object j in node i. |
| C[(x)\vec]i | communication cost between customer [(x)\vec] and node i. |
| p[(x)\vec]ij | Assignment of customer [(x)\vec] to node i for object j. |
| m | Total weight of the customers. |
| L | Minimum allocatable resource. |
| Dij | Demand in node i for object j. |
| c | Total number of cached files. |
| r | Utilization of the caching strategy. |
| D | Communication cost. |
| [^(D)] | Fuzzy objective function. |
| lj* | Allocation for object j in the entire network. |
| jij | Mediator variable defined in (23). |
| wij | Mediator variable defined in (31). |
| y[(x)\vec]i | Mediator variable defined in (34). |